Geenrative AI
How do large language models work?
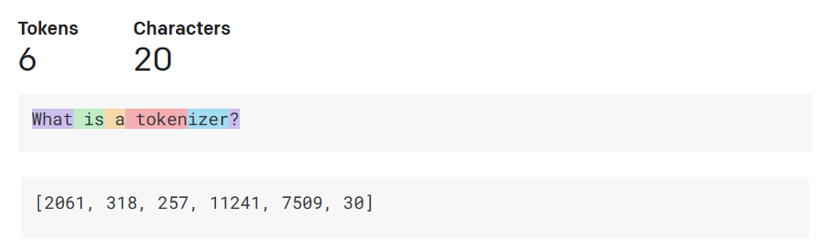
Tokenizer, text to numbers
Large Language Models receive a text as input and generate a text as output. However, being statistical models, they work much better with numbers than text sequences. That’s why every input to the model is processed by a tokenizer, before being used by the core model. A token is a chunk of text – consisting of a variable number of characters, so the tokenizer's main task is splitting the input into an array of tokens. Then, each token is mapped with a token index, which is the integer encoding of the original text chunk.
Predicting output tokens
Given n tokens as input (with max n varying from one model to another), the model is able to predict one token as output. This token is then incorporated into the input of the next iteration, in an expanding window pattern
Selection process, probability distribution
The output token is chosen by the model according to its probability of occurring after the current text sequence
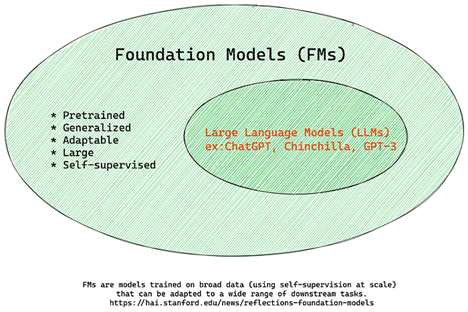
Foundation Models versus LLMs
The term Foundation Model was coined by Stanford researchers and defined as an AI model that follows some criteria, such as:
- They are trained using unsupervised learning or self-supervised learning, meaning they are trained on unlabeled multi-modal data, and they do not require human annotation or labeling of data for their training process.
- They are very large models, based on very deep neural networks trained on billions of parameters.
- They are normally intended to serve as a
foundationfor other models, meaning they can be used as a starting point for other models to be built on top of, which can be done by fine-tuning.